There are new buzz words that popup all the time in the DevOps world. In the last few years one of those words that came up was Pipeline as Code. Everything is coming down to being able to turn it into code. As developers this has always been a natural step for us because we have always begun with code that then gets compiled and turned into working software. More than a decade ago there was a big push to try and re-train folks who worked on databases (DBA’s) to think in terms of database as code and keep that code in Source Control the one single source of truth. Since then you have probably heard of Infrastructure as Code and yes these are the various machines which have been virtualized and there is code that we can write that will create that machine repeatedly and with the same successful results. Today I want to talk about Pipeline as code.
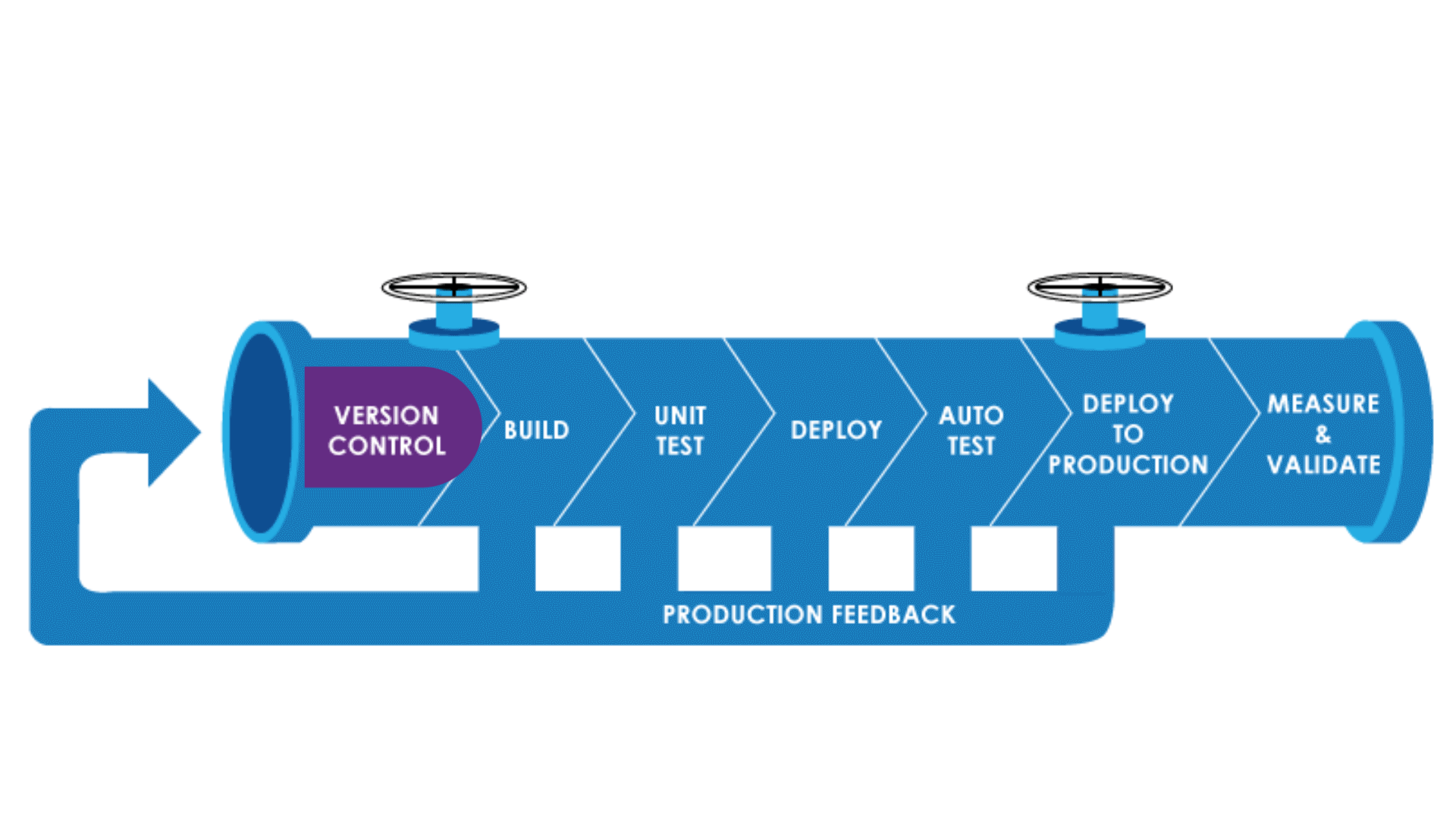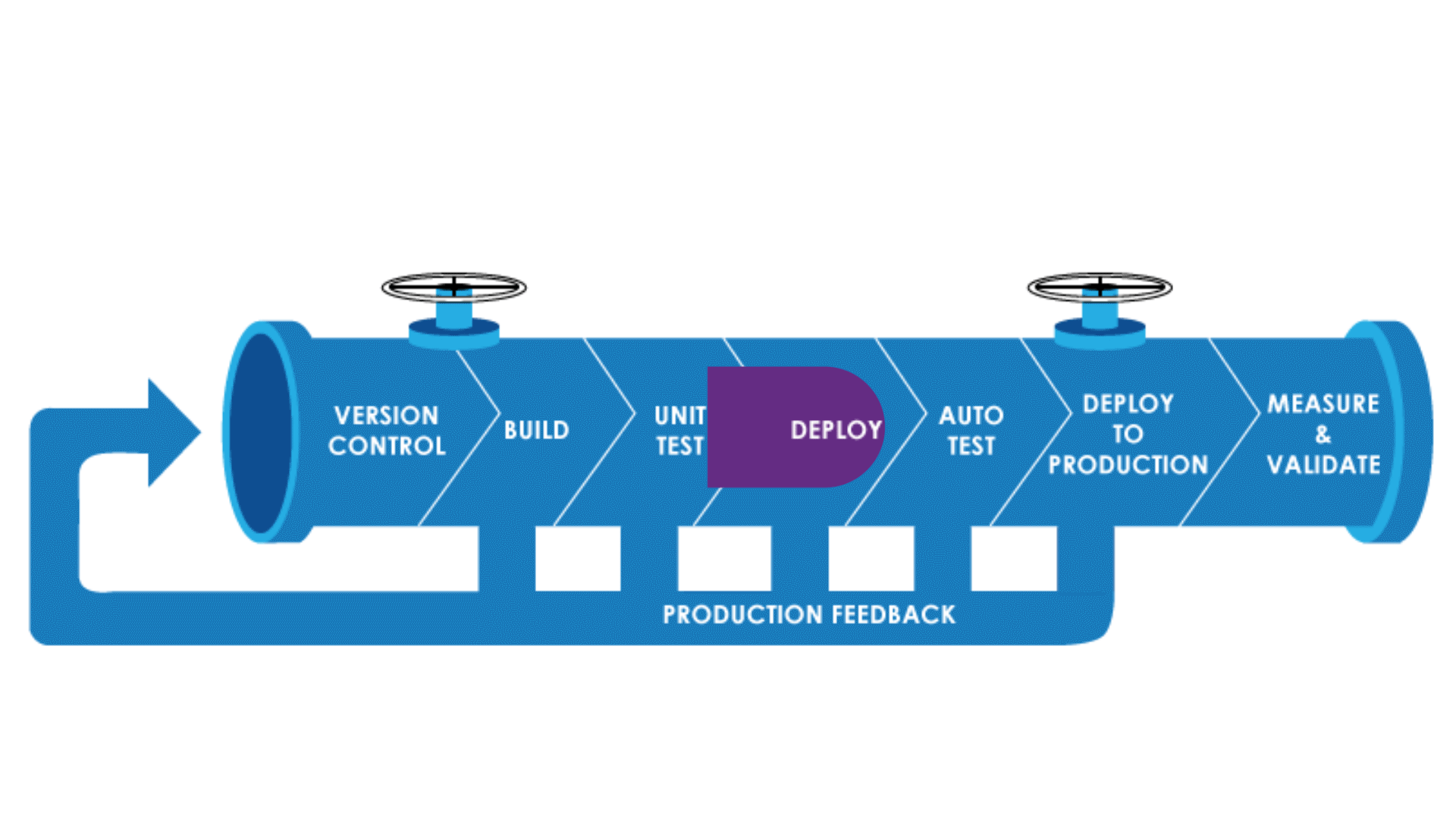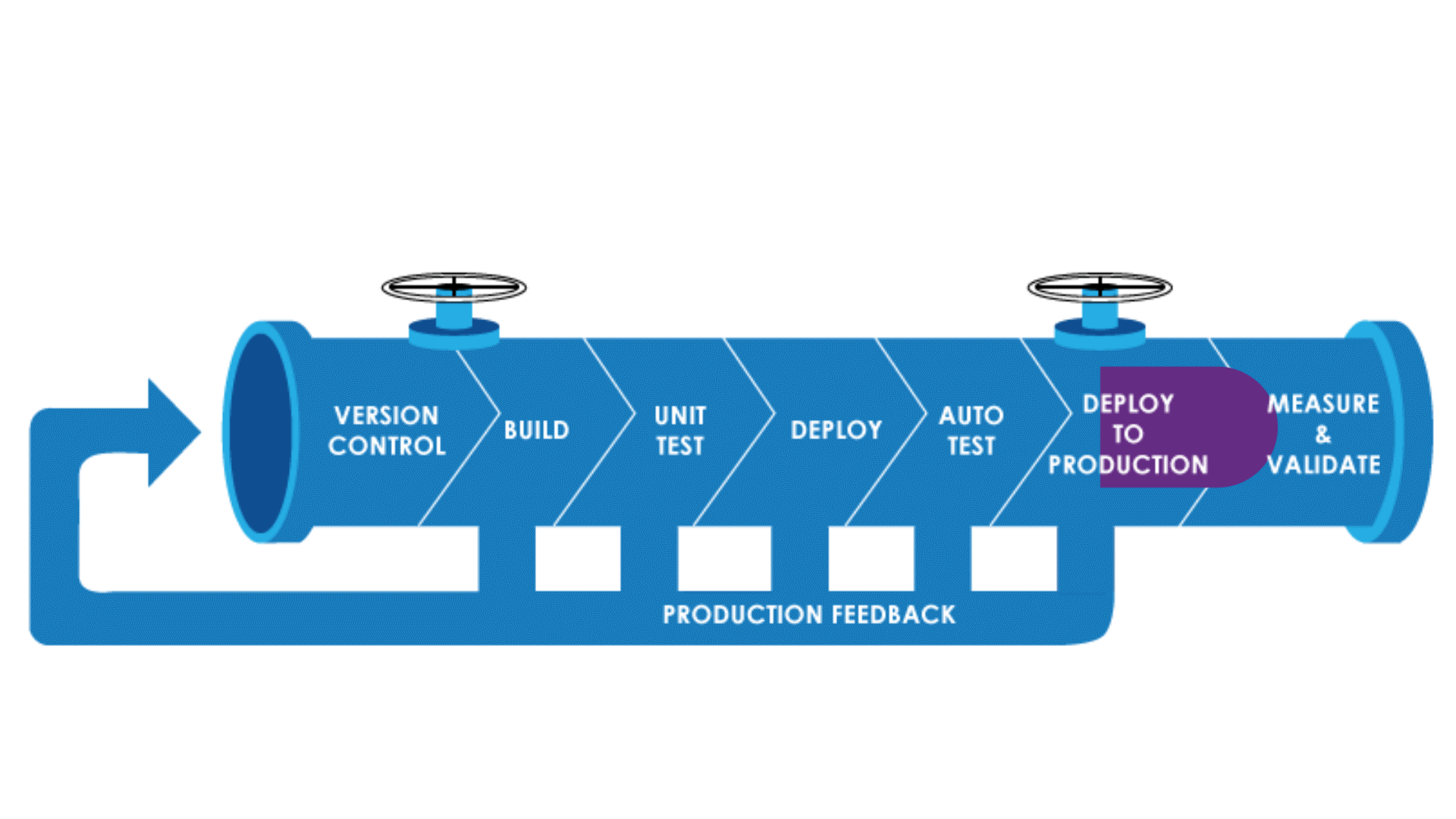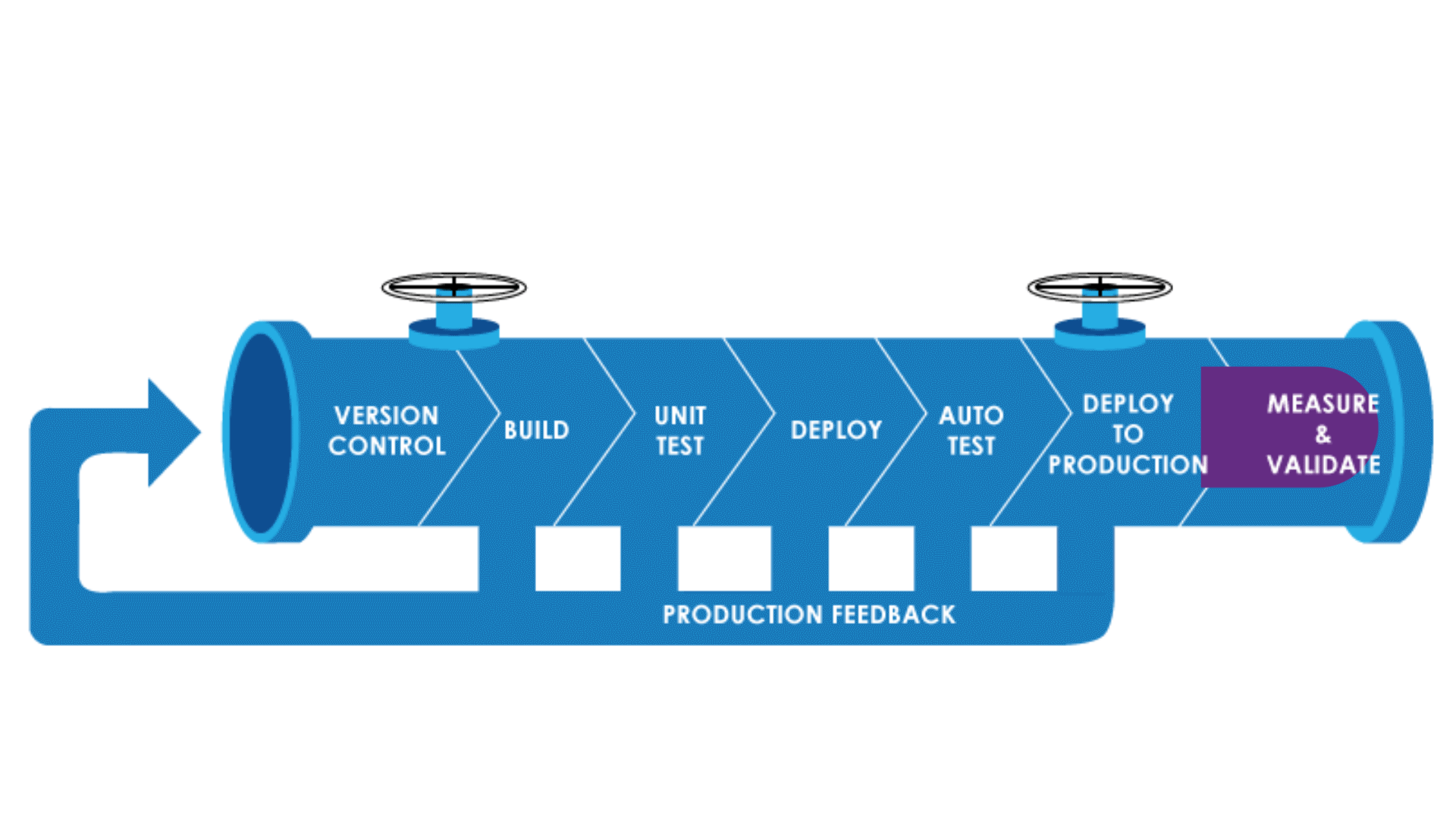
Why Pipeline As Code?
There is always an advantage to anything that you put into source control. With that you get the history of how those changes came together in the code. Ever wonder how a bug got fixed, what was changed to make that happen? Or, even better yet, you have been working on something for a while and suddenly you realize that it no longer compiles, builds, or runs and you can’t remember what you might have changed to break it. These are just some of the things that history out of source control can give to you. Then there is the sharing aspect of source control, when you push your code up to the remote repository your team members can get your latest changes and maybe even put some of their finishing touches on it or maybe they can fix that issue you had. With pipeline as code and stored in source control it also means that it travels with your source. Say you are working in a new environment and you want to change the instance of the build machine (which is where the build definition would typically live) but instead you just need to point to your Jenkinsfile which contains your pipeline and if all the dependencies can be resolved you can get this same pipeline working in this new environment.
However, I think the biggest gain that you get from pipeline as code is the fact that you can create a new branch and that means that your pipeline is also part of the new branch. You could add new aspects to the pipeline that would only make sense in this new pipeline and do not affect other work that might start failing if you messed with the one and only build definition for this project. Then when you go through the proper pull request and merge your changes with master, the new feature that you wrote and the dependent pipeline changes move together into master. Basically you could have a situation where new big changes to the project could be worked on and go through the whole normal CI/CD cycle without breaking anything old or new. With that, lets go back to the history for a minute. That would mean that if we pulled up a commit from several months back, it would contain the appropriate build pipeline for that version of the source. I have had many times in the earlier days of my career as a developer struggling with the build on an older version of the code to try and remember what all changed in the build pipeline so that we can build this once again.
Another thing that pipeline as code solves are licening issues. If you happen to move to the commercial Cloudbees Jenkins which has a lot of important additional features that cater to the Enterprise. Things like a single central server that rules them all, addresses many security concerns and allows you to manage the plugin proliferation of bad and good plugins by only allowing plugins that have been approved by Cloudbees and the Security Team. However, unlike the open source Jenkins all those who access the Cloudbees Jenkins needs a license. If your pipeline is stored in source control you would just need to make your modifications there you would not need access to Cloudbees Jenkins. This really reduces the number of people that would actually need a license.
Pipeline as code solves all that so what would it look like, lets look at that next.
Declarative Pipeline
I have been working with Jenkins for the last couple of months which might seem strange if you have been following me for a long time. In the past I have always been pretty much centered around TFS and lately more Azure DevOps (Same product, different name). Believe it or not there are a lot of Jenkin Servers out there in the world of DevOps so some of the syntax that I will be displaying a little later in this post will be from a Jenkinsfile but the concept is the same.
In the Jenkins world they have two kinds of pipeline as code formats. They have a “Scripted Pipeline” which is a script written in groovy which controls the whole process. If you are comfortable with groovy you might be tempted to go this route. We are not going to go there for this post we are going to go with the “Declarative Pipeline” as this also falls in line with the yaml pipelines of Azure DevOps. The declarative nature of this pipeline is that it sort of describes what should happen in a declarative way not like the Scripted Pipeline that also manages the how we build it.
pipeline {
agent any
parameters {
string( name: 'semver', defaultValue: '1.0.0',
description: 'the resulting semver version number after running gitversion on the source at GitHub')
string( name: 'branchname', defaultValue: 'master',
description: 'the actual branch name that triggered the build as precurred from gitVersion')
}
environment {
RELEASE='1.12.0'
BRANCH_NAME="${params.branchname}"
}
stages {
stage('Build'){
steps {
sh 'chmod +x ./build/ci/02-build.sh'
sh './build/ci/02-build.sh'
}
}
stage('Publish-Testing'){
steps {
sh 'chmod +x ./build/ci/03-publish-testing.sh'
sh "./build/ci/03-publish-testing.sh ${params.semver}"
}
}
stage('Publish'){
when {
environment name: 'BRANCH_NAME', value: 'master'
}
steps {
sh 'chmod +x ./build/ci/03-publish.sh'
sh "./build/ci/03-publish.sh ${params.semver}"
}
}
stage('Deploy'){
steps {
sh 'chmod +x ./build/ci/04-deploy.sh'
sh "./build/ci/04-deploy.sh ${params.semver}"
}
}
stage('Release'){
agent{
label 'AWS-Jenkins-Slave'
}
when {
environment name: 'BRANCH_NAME', value: 'master'
}
steps {
sh 'chmod +x ./build/ci/04-release.sh'
sh "./build/ci/04-release.sh ${params.semver}"
}
}
}
}
This is taken from my current Jenkinsfile that I use to build and deploy this Blog site. I think it is pretty simple and easy to understand. There are some interesting things going on here that I will write about in a later post. My projects that I built have gone into a major vendor change. These days I am using a little bit from Azure, AWS and Google Cloud. In this case my Jenkins Server lives in a docker container in Google Cloud and I am building the docker images there and deploying my development/test instances in that same docker host. However for Production I am installing a docker image on AWS using a Jenkins agent living in that world called by this master Jenkins in Google Cloud.
The pipeline itself starts with pipeline and a set of curly braces, everything for this pipeline is in those braces. Next we tell it to use any agent that is available. I will say one thing about the agent configuration it is configured to only run jobs there when I have specifically asked it to. Next we have some parameters that are being passed in. Over in GitHub were the source for my Blog lives I have an action script that runs gitVersion and produces a semver version and I include that as a parameter when I call Jenkins with the job name. After this I have some environment variables that I want to set so I am only doing this in one place.
Then the pipeline continues with a stage for each part of the build that it goes through from build to Publish to Deploy and or Release. The builds that are going to production will only go there if the branch of the artifact did come from the master branch. Otherwise it is a development/test image and I don’t want that in production until the post is fully baked.
I think that this is a very important step that everyone who is trying to improve their CI/CD experience needs to take if you are not already doing it. In the Azure DevOps world these would be the yaml builds and the concepts are the same and all the same benefits.